Embeddings, Embedding Models and Vector DB
Unlocking AI’s Understanding: A Developer’s Guide to Embeddings and Vector Databases
As developers, we’re constantly seeking ways to build smarter, more intuitive applications. In the exciting world of AI, especially with the rise of Large Language Models (LLMs), a fundamental concept that empowers these intelligent systems is embeddings. But what exactly are they, how do they work, and why are vector databases becoming increasingly crucial? Let’s dive in!
What are Embeddings? The Language of Machines
Imagine trying to explain the concept of “love” to a computer using only words. It’s difficult because words are symbols, not inherently numerical. This is where embeddings come in.
Embeddings are numerical representations of real-world objects – be it words, sentences, images, audio, or even entire documents. Think of them as dense vectors, which are simply lists of numbers, in a multi-dimensional space. The magic lies in the fact that these numerical representations capture the inherent properties and relationships between the original data points.
1
2
Text: "The cat is sleeping"
Embedding: [0.2, -0.1, 0.8, 0.3, ..., 0.5]
For example, in a word embedding space, words with similar meanings (like “king” and “monarch”) will be located closer to each other, while words with opposite meanings (like “day” and “night”) will be further apart. This spatial relationship allows AI models to understand context and meaning, rather than just matching keywords.
Why are they important?
- Bridge the gap: AI models primarily work with numbers. Embeddings transform complex, unstructured data into a numerical format that models can understand and process.
- Capture semantics: They go beyond simple keyword matching, enabling models to grasp the underlying meaning and relationships in data.
- Enable similarity search: By representing data as vectors, we can easily calculate the “distance” between them. Closer vectors mean higher similarity.
- Dimensionality reduction: They condense high-dimensional data into a lower, more manageable dimension while preserving crucial information, making processing more efficient.
How to Create Embeddings: The Role of Embedding Models
Creating these powerful numerical representations is the job of embedding models. These are typically deep learning models, often neural networks, trained on massive datasets. They learn to map various types of data into these dense vector spaces.
The process generally involves:
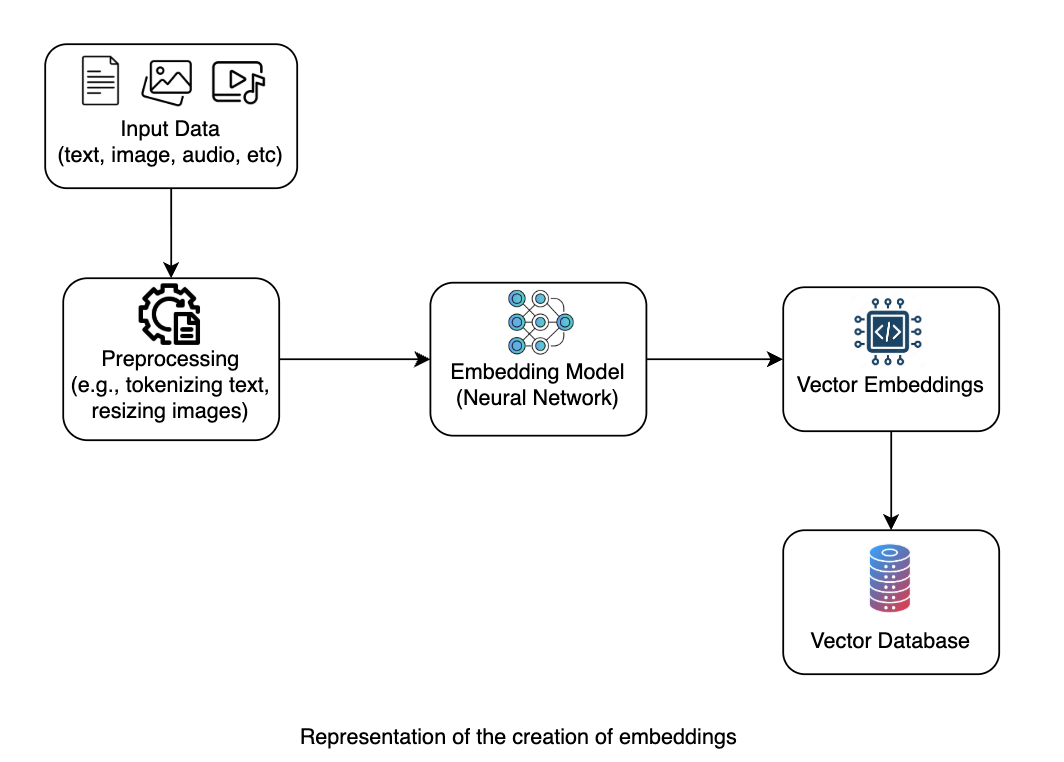
- Inputting raw data: This could be a piece of text, an image, an audio clip, etc.
- Preprocessing: Breaking text into smaller pieces (words or subwords)
- Model processing: The embedding model processes this raw data through its internal architecture (e.g., layers of a neural network).
- Outputting a vector: The final output is a fixed-size numerical vector (the embedding) that encapsulates the semantic information of the input.
- Stored in vector DB: These embeddings can be stored in vector DB for easy manipulation.
Example for Text (Simplified):
Imagine a simple text embedding model. When you feed it the sentence “The cat sat on the mat,” it doesn’t just convert each word into a number independently. Instead, it considers the context. The model learns that “cat” and “kitten” are semantically close, and their embeddings will reflect that proximity.
1
2
3
4
5
6
7
8
# Conceptual example (not runnable code, just for illustration)
from some_embedding_library import EmbeddingModel
model = EmbeddingModel("pre-trained-text-model")
text_data = "The quick brown fox jumps over the lazy dog."
embedding = model.generate_embedding(text_data)
print(embedding) # Output would be a long list of numbers, e.g., [0.123, -0.456, ..., 0.789]
Types of Embedding Models: Tailored for Different Data
Embedding models are specialized for different data types and tasks:
- Word Embeddings: Focus on representing individual words.
- Word2Vec: A classic model that learns word embeddings by predicting words from their context (Skip-gram) or predicting context from a word (CBOW).
- GloVe (Global Vectors for Word Representation): Leverages global word-word co-occurrence statistics from a corpus to learn embeddings.
- FastText: Extends Word2Vec by considering subword information (character n-grams), which helps with rare and out-of-vocabulary words.
- Sentence and Document Embeddings: Capture the meaning of entire sentences, paragraphs, or documents.
- BERT (Bidirectional Encoder Representations from Transformers): A powerful transformer-based model that generates contextual embeddings, meaning the embedding for a word changes based on its surrounding words.
- Universal Sentence Encoder (USE): Developed by Google, it provides dense vector representations for sentences, paragraphs, and short documents.
- Doc2Vec: An extension of Word2Vec for learning document-level embeddings.
- Image Embeddings: Represent visual features and semantic information from images. Often generated by Convolutional Neural Networks (CNNs) like VGG, ResNet, or Inception, pre-trained on large image datasets.
- Audio Embeddings: Convert audio or speech data into vectors, useful for tasks like speech recognition and emotion detection.
- Multimodal Embeddings: A newer and rapidly evolving area where models learn joint embeddings for different data types (e.g., combining text and images, like in CLIP).
For developers, popular and readily available models include:
- OpenAI Embeddings: Offers powerful, pre-trained models accessible via API (e.g.,
text-embedding-3-small,text-embedding-3-large). - Cohere Embed: Provides highly capable multilingual text embedding models.
- Hugging Face Transformers: A vast ecosystem of pre-trained models, including many for embeddings (e.g.,
sentence-transformers/all-MiniLM-L6-v2). - Google’s
gemini-embedding-001(via Vertex AI): A high-performance model for text embeddings.
Practical Applications of Embeddings
Embeddings are the backbone of many modern AI applications:
- Semantic Search: Instead of just keyword matching, you can search for concepts. A search for “smartphone” might also return results for “mobile devices” or “cellphone.”
- Recommendation Systems: By embedding users and items, you can find similar users or recommend items similar to what a user likes.
- Question Answering (Q\&A): Embeddings help Q\&A systems understand the intent of a question and find the most semantically relevant answers from a knowledge base.
- Text Classification: Categorizing documents (e.g., spam detection, sentiment analysis) becomes more accurate when text is represented as rich embeddings.
- Anomaly Detection: Outliers in an embedding space can indicate unusual or fraudulent activity.
- Clustering: Grouping similar data points together for analysis or organization.
Enter the Vector Database: Storing and Searching Embeddings
You’ve generated these amazing numerical representations. Now what? You need a place to store them and, more importantly, efficiently search through them. This is where vector databases come in.
A vector database is a specialized database designed to store, manage, and index high-dimensional vector data (embeddings). Unlike traditional relational databases that excel at structured data and exact matches, vector databases are built for similarity search based on the proximity of vectors in a multi-dimensional space.
How they work:
- Ingestion: You feed your embeddings (along with any associated metadata) into the vector database.
- Indexing: The database indexes these vectors using specialized algorithms (e.g., HNSW, Annoy, Faiss) that optimize for fast similarity search in high-dimensional spaces. This is crucial because a brute-force comparison of every vector would be too slow for large datasets.
- Querying: When a user performs a search (e.g., “find documents similar to this query”), the query itself is first converted into an embedding.
- Similarity Search: The vector database then efficiently finds the closest vectors to the query embedding based on a chosen distance metric (e.g., cosine similarity, Euclidean distance).
- Retrieval: The database returns the original data (or references to it) associated with the most similar embeddings.
Why use a vector database?
- Scalability: Designed to handle billions of vectors and high query throughput.
- Speed: Optimized for low-latency similarity searches, crucial for real-time AI applications.
- Semantic Understanding: Enables search and retrieval based on meaning, not just keywords.
- Complementary to LLMs: They are a core component of RAG (Retrieval Augmented Generation) systems, allowing LLMs to access and incorporate external, up-to-date information.
Popular Vector Databases for Developers:
- Pinecone: A popular managed vector database service.
- Weaviate: An open-source vector database that also includes a GraphQL API.
- Qdrant: Another open-source vector similarity search engine.
- Milvus: A widely adopted open-source vector database built for AI applications.
- Chroma: A lightweight, easy-to-use open-source vector database.
Putting it All Together: A Simple Workflow
- Choose your data: What are you trying to embed (text, images, etc.)?
- Select an embedding model: Pick a model suitable for your data type and task (e.g., OpenAI’s
text-embedding-3-smallfor text). - Generate embeddings: Use the chosen model to convert your data into numerical vectors.
- Store in a vector database: Insert these embeddings into your chosen vector database.
- Perform similarity searches: When a user queries, convert their query into an embedding and use the vector database to find semantically similar results.
Hands-On Implementation
Let’s build a simple embedding system using Python:
Step 1: Install Required Libraries
1
pip install sentence-transformers chromadb numpy
Step 2: Create Embeddings
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Sample documents
documents = [
"The quick brown fox jumps over the lazy dog",
"Machine learning is transforming technology",
"Python is a versatile programming language",
"Artificial intelligence helps solve complex problems",
"Dogs are loyal and friendly animals"
]
# Create embeddings
embeddings = model.encode(documents)
print(f"Created {len(embeddings)} embeddings")
print(f"Each embedding has {len(embeddings[0])} dimensions")
Step 3: Store in Vector Database
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import chromadb
# Initialize ChromaDB
client = chromadb.Client()
collection = client.create_collection("my_documents")
# Add documents with embeddings
collection.add(
documents=documents,
embeddings=embeddings.tolist(),
ids=[f"doc_{i}" for i in range(len(documents))]
)
print("Documents stored in vector database!")
Step 4: Search Similar Documents
1
2
3
4
5
6
7
8
9
10
11
12
13
# Search for similar documents
query = "Programming languages and coding"
query_embedding = model.encode([query])
results = collection.query(
query_embeddings=query_embedding.tolist(),
n_results=2
)
print(f"Query: {query}")
print("Similar documents:")
for doc, distance in zip(results['documents'][0], results['distances'][0]):
print(f"- {doc} (distance: {distance:.3f})")
Step 5: Calculate Similarity Manually
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from sklearn.metrics.pairwise import cosine_similarity
def find_similar_documents(query_text, documents, model, top_k=3):
# Create embeddings
doc_embeddings = model.encode(documents)
query_embedding = model.encode([query_text])
# Calculate similarity scores
similarities = cosine_similarity(query_embedding, doc_embeddings)[0]
# Get top results
top_indices = np.argsort(similarities)[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
'document': documents[idx],
'similarity': similarities[idx]
})
return results
# Example usage
query = "AI and machine learning"
similar_docs = find_similar_documents(query, documents, model)
for i, result in enumerate(similar_docs):
print(f"{i+1}. {result['document']}")
print(f" Similarity: {result['similarity']:.3f}\n")
Conclusion
Embeddings are the unsung heroes of modern AI, transforming complex data into a language that machines can understand. By representing information as dense vectors in a meaningful way, they unlock powerful capabilities like semantic search, intelligent recommendations, and advanced natural language processing. When combined with specialized vector databases, developers have a robust toolkit to build intelligent applications that truly grasp the nuances of human language and real-world data. So, go forth and embed! The future of AI is waiting.